The goal of washopenresearch is to provide an overview of open research data related to Water Sanitation and Hygiene (WASH). The current version contains two datasets from the following sources:
-
washdev: Open access journal Journal of Water, Sanitation and Hygiene for Development -
uncnewsletter: Research section of the newsletter North Carolina Water News

Installation
You can install the development version of washopenresearch from GitHub with:
# install.packages("devtools")
devtools::install_github("openwashdata/washopenresearch")Alternatively, you can download the individual datasets as a CSV or XLSX file from the table below.
| dataset | CSV | XLSX |
|---|---|---|
| washdev | Download CSV | Download XLSX |
| uncnewsletter | Download CSV | Download XLSX |
Data
The package provides access to two datasets washdev and uncnewsletter. Each dataset collects information on scientific articles about (1) article metadata (e.g. title, first author, correspondence author), (2) supplementary material information, (3) data availability statement, and (4) semantic information (e.g. keywords).
washdev
The dataset washdev contains data on open access articles of the Journal of Water, Sanitation & Hygiene for Development (Vol.1 Issue 1 - Vol.13 Issue 11). It has 924 observations from March 2011 to November 2023.
washdev |>
head(3) |>
gt::gt() |>
gt::as_raw_html()| paperid | volume | issue | paper_url | journal | title | published_year | is_supp | num_supp | supp_file_type | supp_url | num_authors | first_author_name | first_author_affiliation | first_author_affiliation_country | first_author_email | first_author_orcid | correspondence_author_name | correspondence_author_affiliation | correspondence_author_affiliation_country | correspondence_author_email | correspondence_author_orcid | has_das | das | das_type | das_repo_url | keywords | url_source |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
For an overview of the variable names, see the following table.
| variable_name | variable_type | description |
|---|---|---|
| paperid | integer | ID number of the paper on the journal website |
| volume | integer | Volume number of the journal |
| issue | integer | Issue number of the journal |
| paper_url | character | Official website url of the paper |
| journal | character | Full name of the journal |
| title | character | Title of the paper |
| published_year | integer | Year of publication |
| is_supp | logical | Whether the paper has supplementary materials |
| num_supp | integer | Number of supplementary material files |
| supp_file_type | list | File type of the supplementary materials |
| supp_url | character | Website url of the supplementary materials |
| num_authors | integer | Number of the authors |
| first_author_name | character | Name of the first author |
| first_author_affiliation | character | Academic affiliation of the first author |
| first_author_affiliation_region | character | Country or region of the first author parsed from first_author_affiliation variable |
| first_author_email | character | Email of the first author |
| first_author_orcid | character | ORCID of the first author |
| correspondence_author_name | character | Name of the correspondence author |
| correspondence_author_affiliation | character | Academic affiliation of the correspondence author |
| correspondence_author_affiliation_region | character | Country or region of the correspondence author parsed from correspondence_author_affiliation variable |
| correspondence_author_email | character | Email of the correspondence author |
| correspondence_author_orcid | character | ORCID of the correspondence author |
| has_das | logical | Whether the paper has a data availability statement |
| das | character | Original data availability statement of the paper. NA if it does not have a data availability statement. |
| das_type | factor | Type of the data availability statement including “in paper”(data in full paper scope like supplementary material or appendix or main content) “on request”(data available on request to the authors) “available in online repository”(data is shared in a public online repository) “not shareable”(data is not shareable). NA if it does not have a data availability statement. |
| das_repo_url | list | Website url of the data if the relevant data of the paper is shared on a public repository |
| keywords | list | List of keywords of the paper |
| url_source | character | Publisher website of the paper |
uncnewsletter
The dataset uncnewsletter contains data on a curated list of articles published at the Research section of the newsletter North Carolina Water News. It has 173 observations from 2020 to 2023.
uncnewsletter |>
head(3) |>
gt::gt() |>
gt::as_raw_html()| paperid | issue_url | paper_url | url_source | journal | title | published_year | is_supp | num_supp | supp_file_type | supp_url | num_authors | first_author_name | first_author_affiliation | first_author_affiliation_country | first_author_email | first_author_orcid | correspondence_author_name | correspondence_author_affiliation | correspondence_author_affiliation_country | correspondence_author_email | correspondence_author_orcid | has_das | das | das_type | das_repo_url | citations | keywords |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
For an overview of the variable descriptions, see the following table.
| variable_name | variable_type | description |
|---|---|---|
| paperid | integer | ID number of the paper on the journal website |
| issue_url | integer | Volume number of the journal |
| paper_url | character | Official website url of the paper |
| url_source | character | Publisher website of the paper |
| journal | character | Full name of the journal |
| title | character | Title of the paper |
| published_year | integer | Year of publication |
| is_supp | logical | Whether the paper has supplementary materials |
| num_supp | integer | Number of supplementary material files |
| supp_file_type | list | File type of the supplementary materials |
| supp_url | list | Website url of the supplementary materials |
| num_authors | integer | Number of the authors |
| first_author_name | character | Name of the first author |
| first_author_affiliation | character | Academic affiliation of the first author |
| first_author_affiliation_country | character | Country of the first author directly parsed from first_author_affiliation variable encoded with United Nation names |
| first_author_email | character | Email of the first author |
| first_author_orcid | character | ORCID of the first author |
| correspondence_author_name | character | Name of the correspondence author |
| correspondence_author_affiliation | character | Academic affiliation of the correspondence author |
| correspondence_author_affiliation_country | character | Country or region of the correspondence author directly parsed from correspondence_author_affiliation variable encoded with United Nation names |
| correspondence_author_email | character | Email of the correspondence author |
| correspondence_author_orcid | character | ORCID of the correspondence author |
| has_das | logical | Whether the paper has a data availability statement |
| das | character | Original data availability statement of the paper. NA if it does not have a data availability statement. |
| das_type | factor | Type of the data availability statement including “in paper”(data in full paper scope like supplementary material or appendix or main content) “on request”(data available on request to the authors) “available in online repository”(data is shared in a public online repository) “not shareable”(data is not shareable). NA if it does not have a data availability statement. |
| das_repo_url | list | Website url of the data if the relevant data of the paper is shared on a public repository |
| keywords | list | List of keywords of the paper |
Example
washdev
- What are the top 10 countries(or regions) the first authors from in the Journal of Water, Sanitation and Hygiene for Development?
library(washopenresearch)
washdev |>
filter(!is.na(first_author_affiliation_country)) |>
group_by(first_author_affiliation_country) |>
summarise(count=n()) |>
arrange(desc(count)) |>
head(10) |>
ggplot() +
geom_col(aes(x = reorder(first_author_affiliation_country, count),
y = count)) +
labs(title = "Top 10 countries of first author",
subtitle = "in the Journal of Water, Sanitation and Hygiene for Development",
x = "First Author Country", y = "Count") +
scale_x_discrete(labels = scales::label_wrap(15))+
coord_flip() +
theme_classic()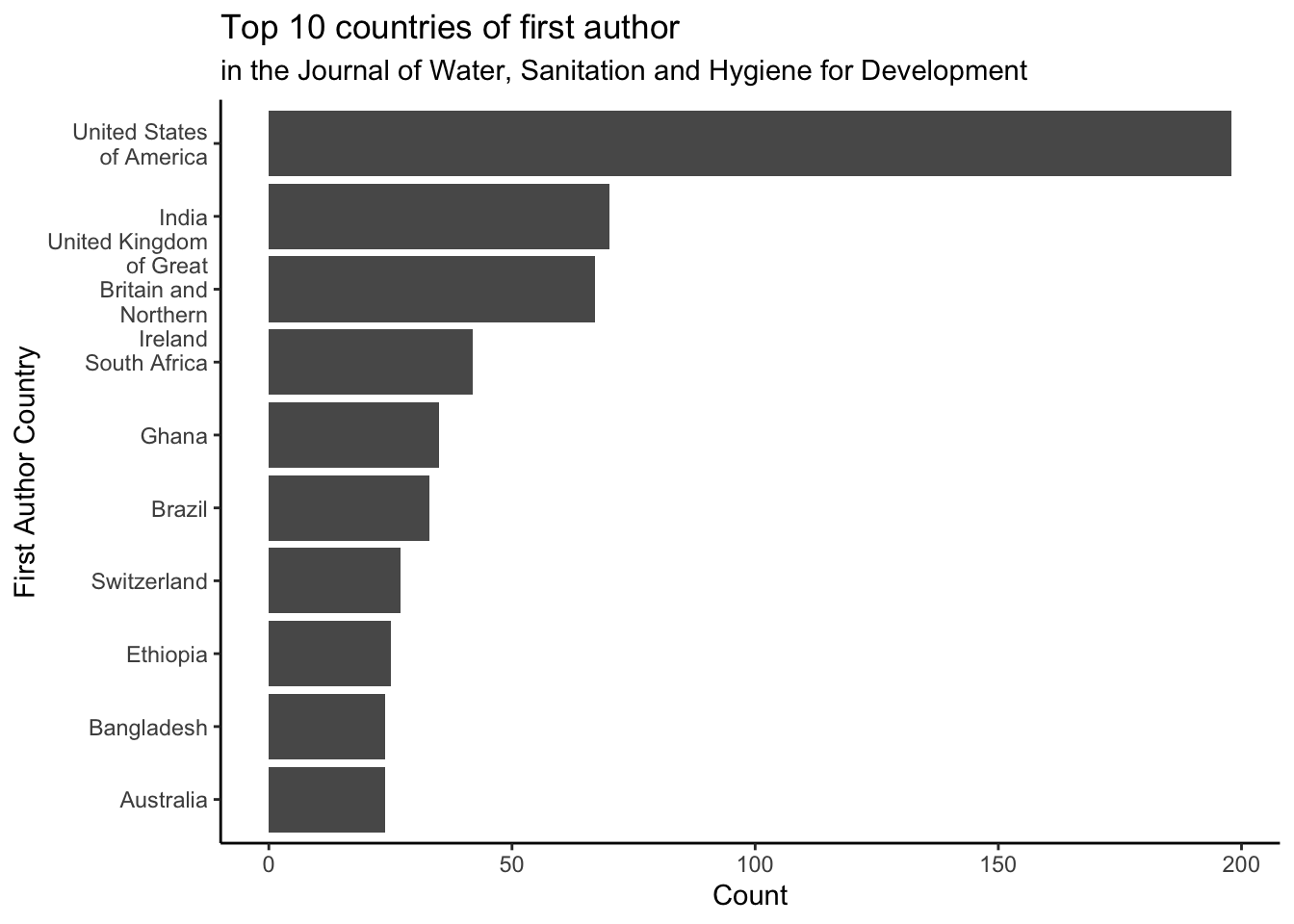
- What are the top choices of keywords in WASH Dev?
Each publication may provide a list of keywords, typically 5-7, to summarize the topics of the article. Here we compile all keywords and calculate their frequency to be used.
keywords_freq <- washdev$keywords |>
unlist() |>
str_to_lower() |>
table() |>
as.data.frame() |>
as_tibble() |>
arrange(desc(Freq))
# Top 20 keywords
ggplot(data = head(keywords_freq, 20)) +
geom_bar(aes(x = reorder(Var1, Freq), y=Freq), stat = "identity") +
coord_flip() +
labs(title = "Top 20 Keywords in WASH Dev Journal", x = "Keywords", y = "Count") +
theme_bw()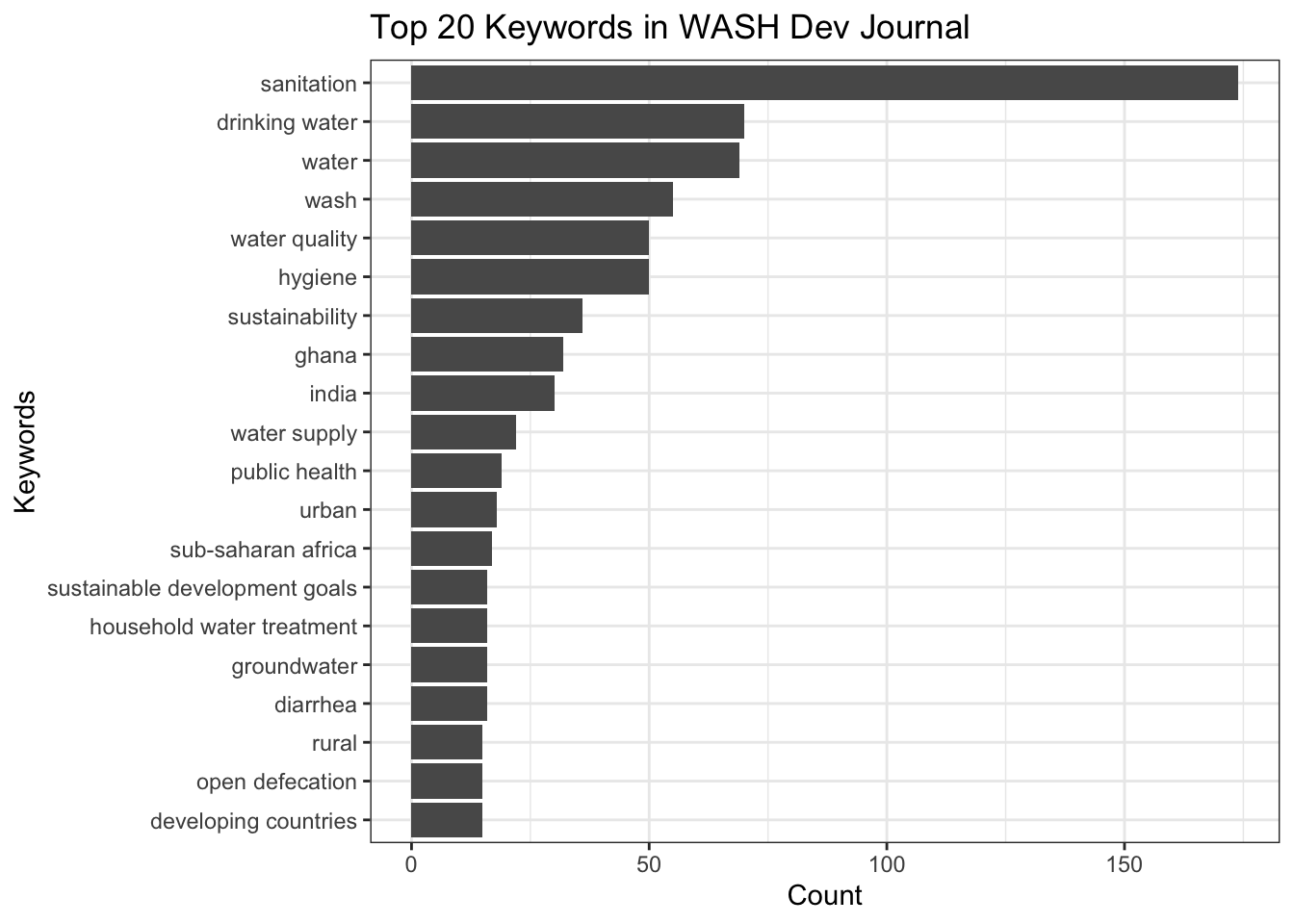
uncnewsletter
- What are the top 10 source websites of the publications selected by the newsletter?
uncnewsletter |>
group_by(url_source) |>
summarise(count=n()) |>
arrange(desc(count)) |>
head(10) |>
ggplot() +
geom_col(aes(x = reorder(url_source, count),
y = count)) +
labs(title = "Top 10 publication websites",
subtitle = "in the selection of North Carolina Water News",
x = "Website URL", y = "Count") +
scale_x_discrete(labels = scales::label_wrap(15))+
coord_flip() +
theme_classic()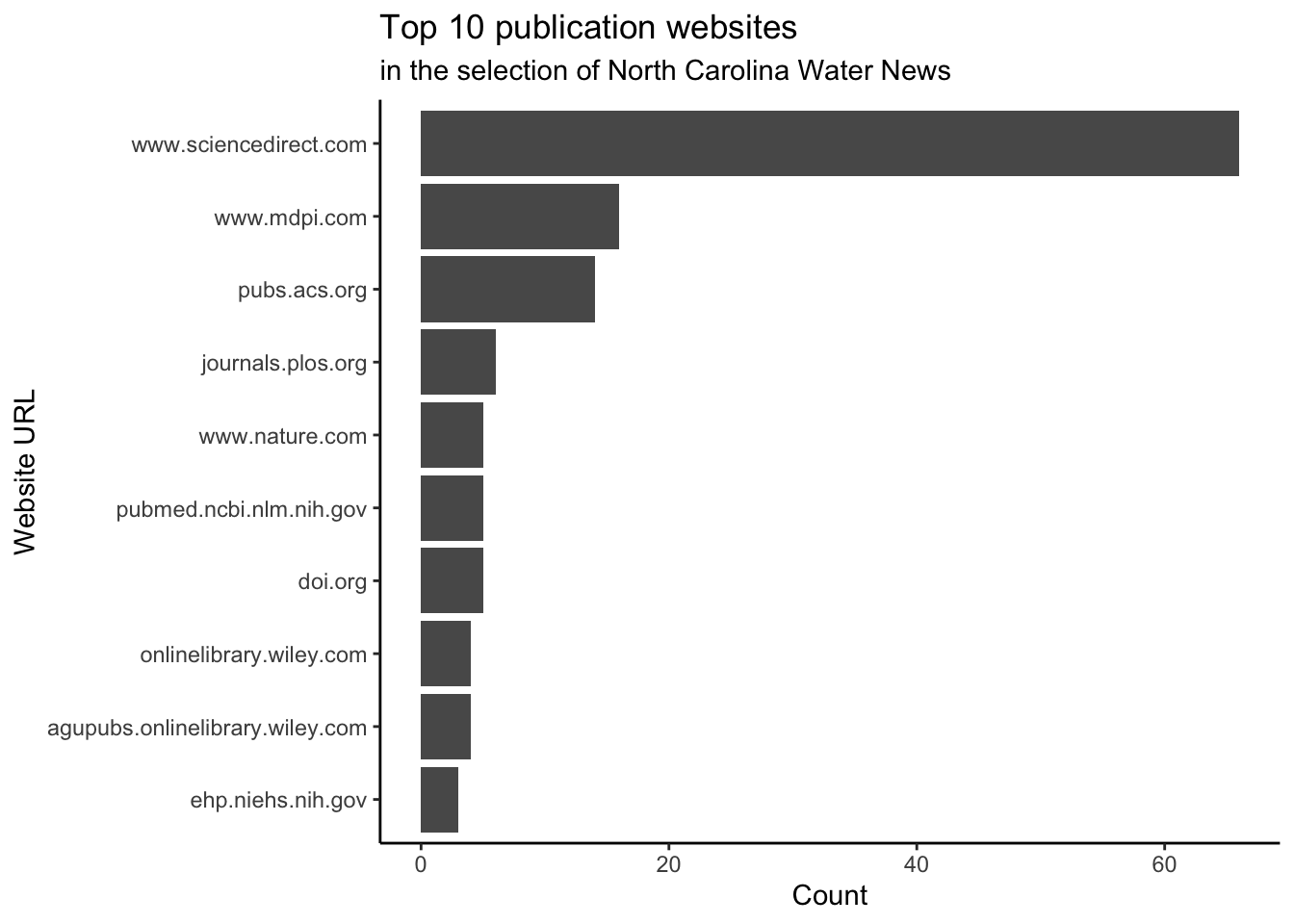
Method
We describe the raw data collection procedure of each dataset in this section. To reproduce the collection, you need to have python3 installed and install python libraries
washdev
The collection of washdev is via web scraping using Python. The script can be found in inst/python/washdev_scraping.py. First, each publication link is scraped from iterating the table of contents of all volumes. This step delivers a table containing the variables paper ID, volume number, issue number, publication url, journal title, publication title, and published year. This table will be merged to get the final dataset.
Then, for each publication, we retrieve the needed variables from the publication’s html file using the publication url. The retrieval is rule-based to find the relevant fields (e.g. supplementary materials) and extract the value.
uncnewsletter
The collection of uncnewsletter is a combination of web scraping and manual annotation. We first use the newsletter archive to scrape all publication website links. The code can be found at inst/python/uncnewsletter_scraping.py. Two annotators worked on the manual extraction of the needed variables on these publications. For each publication, an annotator follows the guide to fill in the value on an collaborative spreadsheet. The guide is converted into the data dictionary for this dataset.
License
Data are available as CC-BY.
Citation
Please cite this package using:
citation("washopenresearch")
#> To cite package 'washopenresearch' in publications use:
#>
#> Zhong M, Luz L, Schöbitz L (2024). "washopenresearch: Dataset about
#> open research data information in Water, Sanitation, and Hygiene."
#> doi:10.5281/zenodo.11185699
#> <https://doi.org/10.5281/zenodo.11185699>,
#> <https://github.com/openwashdata/washopenresearch>.
#>
#> A BibTeX entry for LaTeX users is
#>
#> @Misc{zhong_etall:2024,
#> title = {washopenresearch: Dataset about open research data information in Water, Sanitation, and Hygiene},
#> author = {Mian Zhong and Ludwig Luz and Lars Schöbitz},
#> year = {2024},
#> doi = {10.5281/zenodo.11185699},
#> url = {https://github.com/openwashdata/washopenresearch},
#> abstract = {The goal of washopenresearch is to provide an overview of open research data related to Water Sanitation and Hygiene (WASH). The package provides access to two datasets `washdev` and `uncnewsletter`. Each dataset collects information on scientific articles about (1) article metadata (e.g. title, first author, correspondence author), (2) supplementary material information, (3) data availability statement, and (4) semantic information (e.g. keywords).},
#> keywords = {open-data,open-research-data,open-science,openwashdata,sanitation,wash},
#> version = {0.0.1},
#> }